Best practices for implementing with PROCESIO
Start with outcomes: one measurable KPI per process (e.g., “reduce onboarding cycle time by 30%”).
A) General Principles & Know-How
1) Frame the work
-
Start with outcomes: one measurable KPI per process (e.g., “reduce onboarding cycle time by 30%”).
-
Map the as-is → to-be: capture triggers, systems, data contracts, SLAs, exceptions.
-
Define RACI (Responsible | Accountable | Consulted| Informed) early: business owner, builder(s), reviewer, approver, operator.
Quick PROCESIO-flavored example
Automating “CRM customer upsert” via PROCESIO:
| Activity | Product Owner | PROCESIO Builder | Reviewer/QA | Security/IT | Sales Ops |
|---|---|---|---|---|---|
| Define KPI & scope | A | I | C | I | C |
| Build process & connectors | I | R | C | C | I |
| Data mapping & validation rules | C | R | C | I | A |
| UAT & sign-off | A | R | C | I | C |
| Prod release & monitoring | A | R | C | C | I |
2) Solution design
-
Modularize: one main process + small reusable subprocesses (auth, paging, validation, notifications). | think in terms of trade-offs:
- Too many sub-processes might result in harder debugging, extra execution time
- No sub-processes result in a monolithic approach (hard debugging, but also potential for re-executing unnecessary steps)
-
Stable contracts: standardize input/output with DTO-style variables; avoid passing raw API payloads between steps.
-
Idempotency: design so a retry won’t create duplicates (use external IDs, dedupe keys).
- Accidentally triggering the process twice should not be impactful on the records
- Think about using error ports for allowing error capture and error logic handling
-
Stateless core: keep state in systems of record; use PROCESIO variables only for transient orchestration.
-
Build your PROCESIO processes so they don’t need to remember anything between runs.
-
Anything you must remember across runs (checkpoints, last-sync time, job status, idempotency keys, approvals, etc.) should live in a durable system of record—the CRM/ERP/ticketing tool itself, or a database you control.
-
Use PROCESIO variables only inside a single execution (to pass data between steps, hold tokens, page cursors, correlation IDs). They’re ephemeral by design.
-
-
Perceived speed for users: It is most important for users to feel they are using a technology that helps them and makes them progress in their daily jobs (not the other way around), and for this, they need to have and use UI that is fast and they do not waste time on waiting for “Procesio” to respond - this will greatly negatively impact the perception of our clients concerning PROCESIO. This is because users cannot possibly know why the PROCESIO Forms are so unresponsive; it must be because of PROCESIO - WE MUST NOT ALLOW THIS SITUATION TO EVER HAPPEN!
-
Secrets management: do not keep secrets in processes! Keep them in the Credential Manager
-
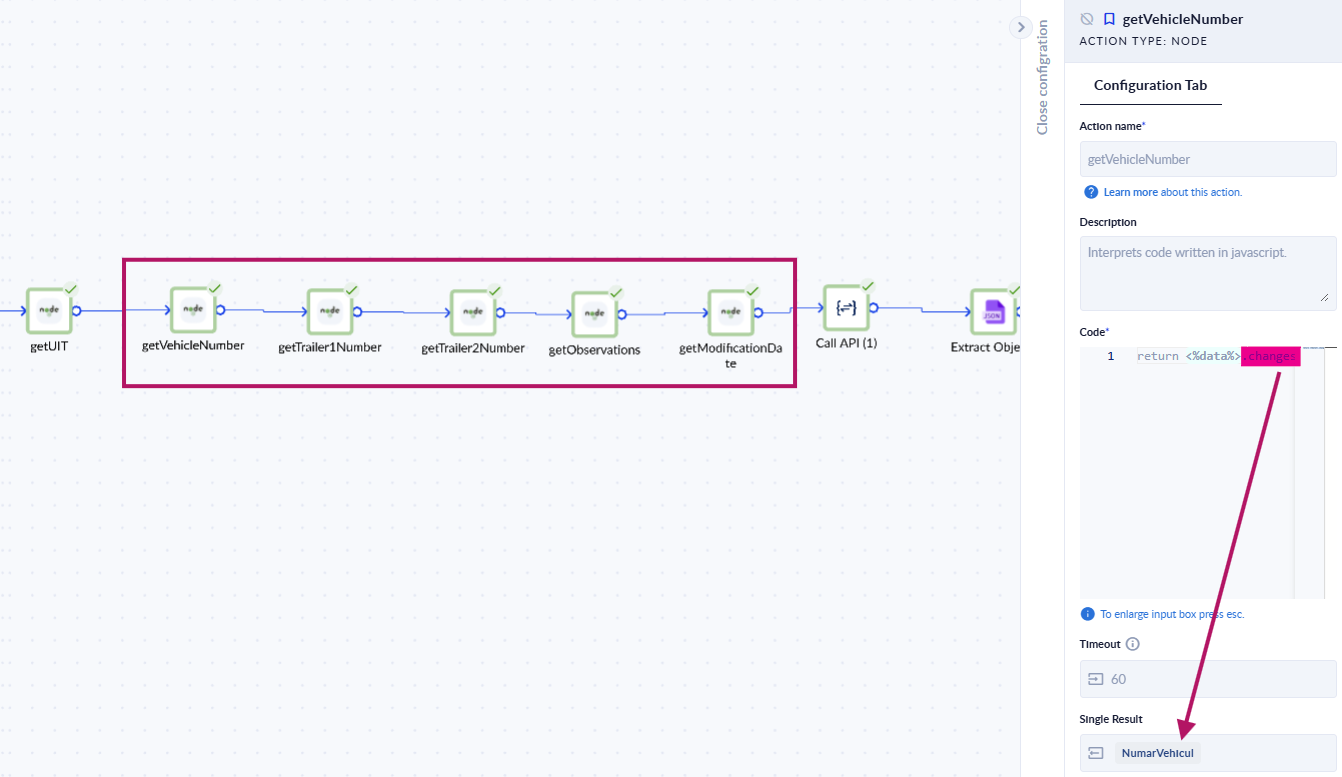
Parameters handling: when we have parameters that we have in multiple processes and that at some point can change (most times all need to change at some point), those parameters need to be set in a single place (e.g., in one process) and then shared everywhere, so once you change the parameter in one place you do not have to change it everywhere but it applies automatically.
Bad example of how not to do it:
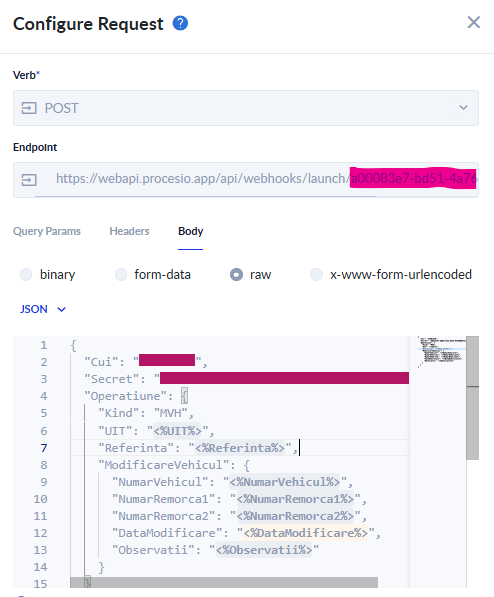
This approach of NOT centralizing parameters (and writing the secrets in plain hardcoded text) will ALWAYS lead to problem, and future effort.
3) Integrations (1–2 days for first system)
Wrap each external API in a reusable subprocess:
- auth-get-token
- <system>-get-by-id, <system>-search, <system>-upsert
- Pagination helper and rate-limit handler
- Implement exponential backoff, idempotency keys, and a standard error object.
- Retires at different growing intervals:
Attempt → wait examples (± jitter):
1 → ~5s 2 → ~10s 3 → ~30s 4 → ~1min
- idempotency keys
Goal: The same logical action runs once—even if your process retries or is triggered twice. For this purpose, use Idempotency keys (dedupe/once-only)
4) Data contracts (ongoing)
- Define DTO variables (e.g., Customer, OrderLine, Address).
- Re-use data model (DM) children of the same DM, where appropriate
5) Robustness
-
Add global try/catch paths via Error Port + Decisional Action. Define appropriate error handling logic within PROCESIO:
- Retryable: retry(max=3, backoff=2^n)
- Business: send to queue + notify owner
- Hard fail: alert, capture context, stop
6) Observability
- Generate a correlation ID at start; pass to all logs/requests.
- Store the process instance ID of the main process when appropriate, set a specific status for it (success/fail, other custom status)
- Add alerts on thresholds (if something is repetitively failing)
7) Document & handover
- Write documentation on each process, think of mapping the order in which processes are triggered (visual map if necessary).
- Think in terms of SOPs (Standard Operating Procedures), so that someone not knowing what happens should be able to debug or follow the logic of the process.
B) Particular Component usage
1) SQL Server Actions
The following image depicts best practices in using the SQL Server action and how to design the SQL statements:
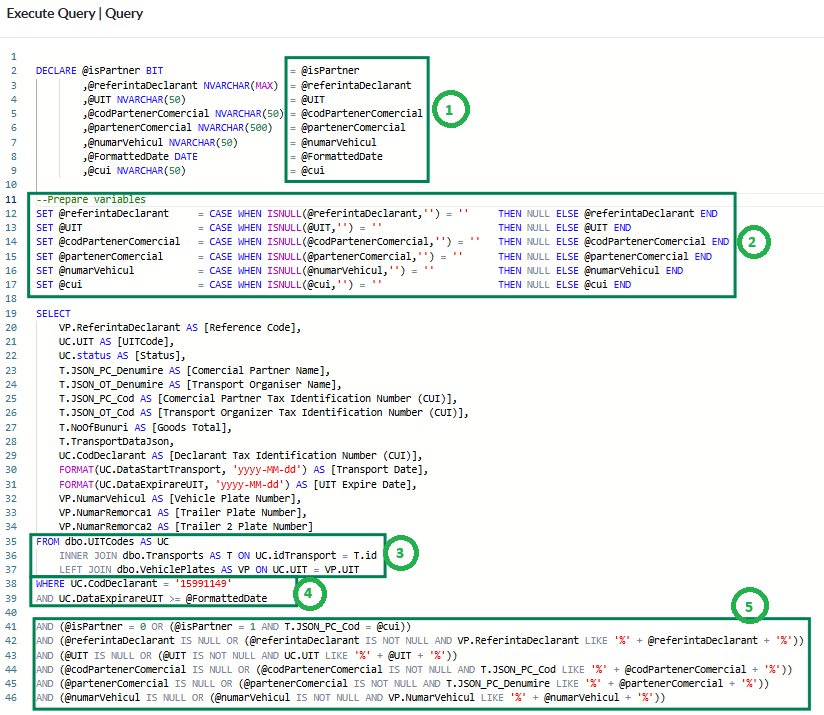
1) Always use the action parameters to inject data into the SQL statement. Centralize all parameters at the beginning of the SQL statement, so it makes it easier to visualize which are the injected values.
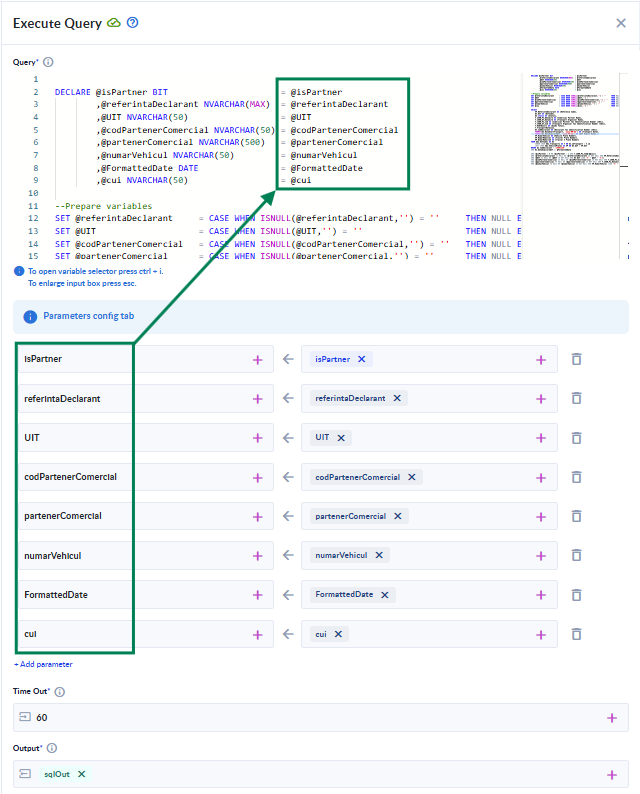
A few notes on how to use parameters:
a) The parameters are always on the RIGHT-hand side of an operation
sql
//Good Practice
SELECT *
FROM Invoices AS I WHERE I.InvoiceId = @Param_InvoiceId
//Good Practice
SET @SQLVariable = @Parameter
=========================================================================================
//Bad Practice
SELECT *, @Param_InvoiceId /*you will get error doing this*/
FROM Invoices AS I WHERE I.InvoiceId = @Param_InvoiceId
//Bad Practice
SET @Parameter = @SQLVariableb) The parameters can have the same name as the names of the internal variables of the SQL statement - the compiler safely knows where to replace the parameters.
c) Use parameters only once in the statement, especially if your parameter names are the same as the internal variable names of the SQL statement.
2) After the SQL parameter injection in the SQL statement, perform a cleaning operation on the SQL variables that hold the data coming from the SQL parameters, to make sure that the rest of the SQL statement performs as expected.
NOTE: The SQL execution engine optimizes the execution plan, but there are many scenarios in which the execution engine cannot determine the best execution plan, so it does not optimize it and executes the statement exactly as it was written. So, the best course of action is to always write the SQL statements in it’s most effective form and this is the scope of the following best practices in writing SQL statements.
3) The SQL statement, if it is a SELECT statement (though the following rules apply nicely to DELETE and UPDATE statements as well), makes sure that the FROM and JOINS are done following the best practices:
a) Select data first from the table with the smallest record set, and the last one should be the one with the largest record set. See examples:
- Good practice:
SELECT * FROM Invoices INNER JOIN InvoiceArticles- Bad practice:
SELECT * FROM InvoiceArticles INNER JOIN Invoicesb) The join conditions should be applied in order from the most restrictive condition to the least restrictive one. See examples:
- Good practice:
SELECT * FROM Invoices AS I
INNER JOIN InvoiceArticles AS IA ON IA.InvoiceId = I.InvoiceId AND IA.ArticleStatus = 1- Bad practice:
SELECT * FROM Invoices AS I
INNER JOIN InvoiceArticles AS IA ON IA.ArticleStatus = 1 AND IA.InvoiceId = I.InvoiceIdc) The order of INNER and LEFT joins is important as well. This is an extension of the rule above (3.b), which is easy to miss, and this is why we mention it separately as well. When possible, use first INNER and then LEFT joins. See examples:
- Good practice:
SELECT * FROM Invoices AS I
/* this join limits the number of remaining rows that the following join will have */
INNER JOIN InvoiceArticles AS IA ON IA.InvoiceId = I.InvoiceId
LEFT JOIN StockHolders AS SH ON SH.InvoiceId = I.InvoiceId- Bad practice:
SELECT * FROM Invoices AS I
/* this join DOES NOT limit the number of remaining rows that the following join will have */
LEFT JOIN StockHolders AS SH ON SH.InvoiceId = I.InvoiceId
INNER JOIN InvoiceArticles AS IA ON IA.InvoiceId = I.InvoiceIdd) Limit the number of JOINs in an SQL statement to 5 - maximum 6 joins! This is important for creating an optimal execution plan for the SQL statement because the SQL execution engine must calculate the possible paths of execution. For instance, 5! = 120, 6! = 720, 7! = 5040, and 8! = 40320. As you can see, adding more joins to the statement makes the execution engine's task of determining an optimum execution plan exponentially harder. If it cannot determine an optimum execution plan, it will default to not optimizing the plan. Therefore, it is very important how you write the statement from the start (there are other reasons for which an optimum execution plan cannot be determined).
4) The WHERE section of an SQL statement should respect the following best practices:
a) The WHERE conditions should be applied in order from the most restrictive condition to the least restrictive one. See examples:
- Good practice:
SELECT * FROM Invoices AS I
WHERE I.InvoiceId = 123
AND I.IssueDate >= '2025-04-11'- Bad practice:
SELECT * FROM Invoices AS I
WHERE I.IssueDate >= '2025-04-11'
AND I.InvoiceId = 123b) Use only pre-calculated values as much as possible, instead of calculating values on the spot. This is a more general rule! See examples:
- Good practice:
SET @var = CASE WHEN ISNULL(@var, '') = '' THEN NULL ELSE @var END
SET @calcFixed = CASE WHEN @var IS NULL THEN 1 ELSE 2 END
SELECT *,
CASE WHEN @calcFixed = 1 THEN I.Col1 ELSE I.Col2 END AS CalcCol
FROM Invoices AS I
WHERE I.column = @variable- Bad practice:
SET @var = CASE WHEN ISNULL(@var, '') = '' THEN NULL ELSE @var END
SET @calcFixed = CASE WHEN @var IS NULL THEN 1 ELSE 2 END
SELECT *,
/*notice that ISNULL function will be used for every result row*/
CASE WHEN ISNULL(@var, '') = '' THEN I.Col1 ELSE I.Col2 END AS CalcCol
FROM Invoices AS I
WHERE I.column = CASE WHEN ISNULL(@var, '') = '' THEN NULL ELSE @var END
/*notice that for every row to be evaluated the CASE condition and the ISNULL function will need to be evaluated as well - the execution engine does not precalculate them and then applies the result for every row, but instead it evaluates it for every row - bad for performance!*/
5) When applying filters in the WHERE section of the SQL statement, respect the following best practices:
- Make sure you clean the filtering parameters before applying them to the filter - see point 2 above.
- Make sure that each condition activates only if there is a filter set for that condition:
- Good practice:
DECLARE @refDec NVARCHAR(MAX) = @refDec,
@UIT NVARCHAR(50) = @UIT
--prepare variable
SET @refDec = CASE WHEN ISNULL(@refDec,'') = '' THEN NULL ELSE @refDec END
SET @UIT = CASE WHEN ISNULL(@UIT,'') = '' THEN NULL ELSE @UIT END
SELECT *
FROM dbo.UITCodes AS UC
LEFT JOIN dbo.VehiclePlates AS VP ON UC.UIT = VP.UIT
WHERE
(@refDec IS NULL
OR (@refDec IS NOT NULL AND VP.ReferintaDeclarant LIKE '%' + @refDec + '%')
)
AND
/*this type of condition takes effect only when there is a filter applied*/
(@UIT IS NULL
OR (@UIT IS NOT NULL AND UC.UIT LIKE '%' + @UIT + '%')
)- Bad practice:
DECLARE @refDec NVARCHAR(MAX) = @refDec,
@UIT NVARCHAR(50) = @UIT
SELECT *
FROM dbo.UITCodes AS UC
LEFT JOIN dbo.VehiclePlates AS VP ON UC.UIT = VP.UIT
WHERE
(VP.ReferintaDeclarant LIKE
CASE
WHEN @refDec = '' OR @refDec IS NULL THEN '%'
ELSE '%' + @refDec + '%'
END)
AND
/*this type of condition ALWAYS takes effect and hits the performance of the SQL statement*/
(UC.UIT LIKE
CASE
WHEN @UIT = '' OR @UIT IS NULL THEN '%'
ELSE '%' + @UIT + '%'
END)2) PROCESIO Forms & Tasks
The following best practice principles should always be followed when building forms with PROCESIO:
- OUTCOME related: Always think about UX (User eXperience) and make sure it is BEST:
- The user should not wait more than 1s on 90% of the clicks they can do on the built UI. For this, follow the following rules:
- Limit the calls made to processes as much as possible. There are enough features in the Forms so that most of the calls made to processes can be avoided.
- When calling a process, make sure the process has a minimum number of actions (ideally 1, still good 3, already bad 5, really bad >5) and that it is highly optimized for speed - see the Process Optimize for Speed section in this document.
- Limit the usage of loading screens triggered by the user action (e.g., click). When possible, use loading visuals only for the sections that are affected by the user action.
- Implement pagination & filtering when tables with a potentially large number of rows are used.
- The user should not wait more than 1-3s on more than 10% of the clicks they can do on the built UI. For this, apply the point a) rules above, and in conjunction (and only after applying them and still the time is >1s) with them, the following rules:
- For complex long-processing tasks, break down the task that takes a longer time into multiple steps so that each does not take longer than 3s, and update visually the UI as each task is finished. For each of the resulting sub-tasks, apply the point a) rules above. This will provide the user with a better experience, as they will perceive the UI as moving faster.
- Do the above until there are no more tasks lasting more than 3s, and the tasks lasting >1s are less than 10% of the actions that a user can trigger (e.g., by click).
- The user should not wait more than 3s on any click EVER. For those situations, an asynchronous mechanism should be implemented, allowing the user to continue their activity and be notified when the task has been completed.
- The user should not wait more than 1s on 90% of the clicks they can do on the built UI. For this, follow the following rules:
3) PROCESIO Optimize for Speed
In the following section, we will show good and bad implementation examples and how to design your processes for speed. Every procesio action takes ~50ms to execute. Some actions natively take longer (such as the “Decisional” action) and others that natively take a shorter time (such as the Numerical “Add” action). An action takes longer to execute for the following reasons:
- We parse/inject into it a large volume of data (a variable containing large data)
- We interact with external systems that take longer to respond (Call API, SQL, FTP)
So, to optimize the processing speed of a process, we need to understand the above and acknowledge that:
- The more actions a process has, the longer it is going to run
- The longer an external system takes to respond, the longer the process is going to run
So, to optimize the processing speed of a process, we need to address the following:
- Reduce the number of actions used at all costs
- Use the actions as effectively as possible (e.g., writing code in the scripting actions)
- Optimize what you are doing in external systems, for example:
- SQL actions: improve the performance of your SQL statements and of the database
- Call API & FTP actions: use them only where necessary if the speed of the process execution is crucial (e.g., when you call the process from a Form and do not want the user to wait)
Below, we will see a bad example in terms of performance and then how to optimize it.
- Bad performance example (it takes ~2s to go through the 5 decisional actions)
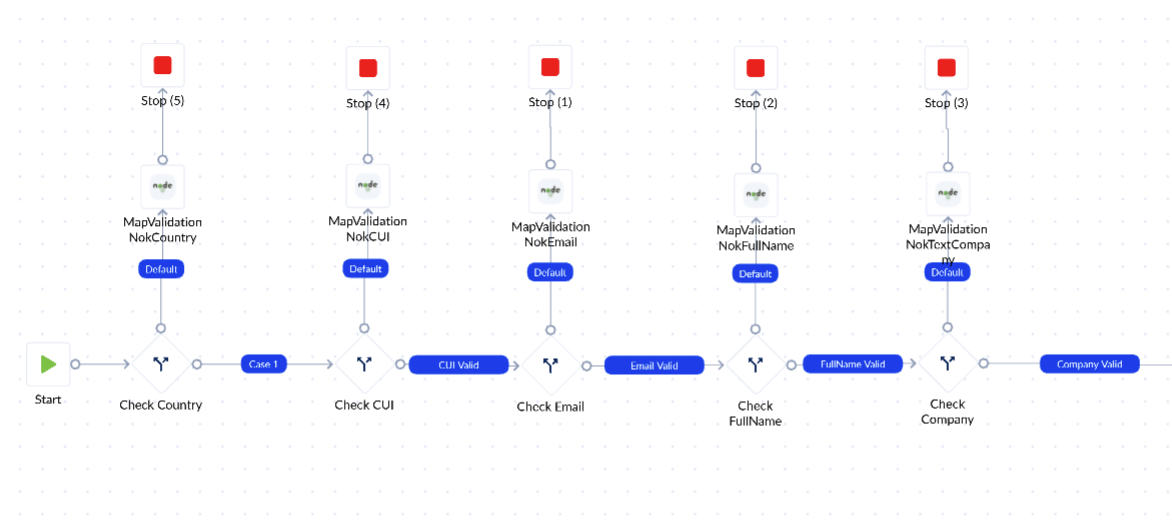
- Optimized version of the process that takes <200 ms to execute, done with a single Decisional action:
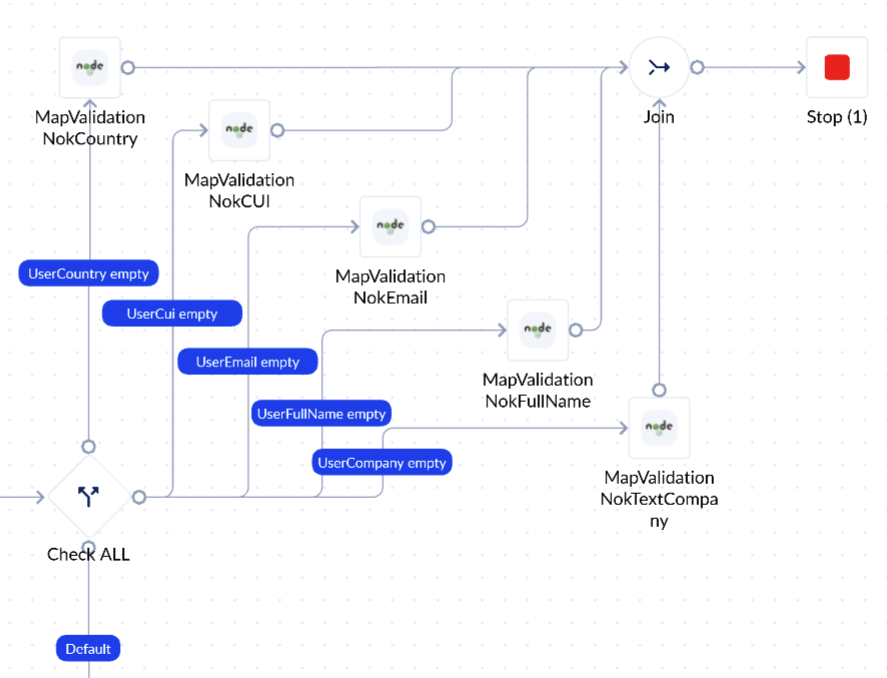
- An even more optimized (best) version of the above could be to use a single (e.g., NodeJS) scripting action that does this by itself.
Another example of bad usage is for extracting data from JSON objects that leads to overcomplicated process logic, overuse of actions, which in turn leads to poor performance and bad design overall: