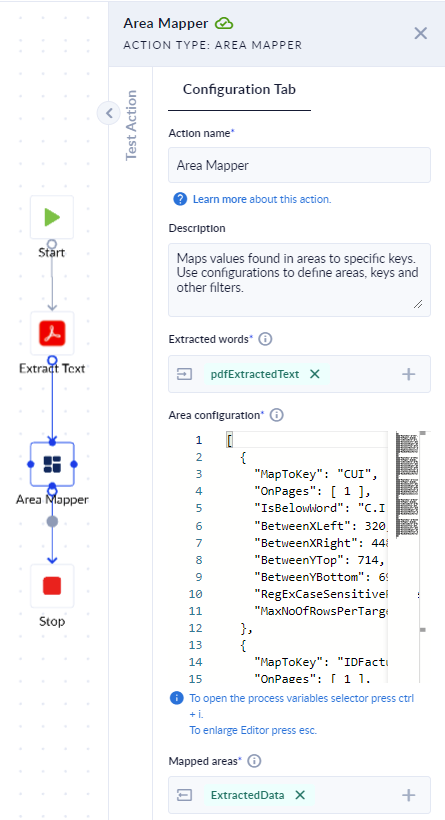
Area Mapper
The Area Mapper action facilitates mapping values found in specific areas of a document to corresponding keys. It involves defining configurations to…
Overview
The Area Mapper action facilitates mapping values found in specific areas of a document to corresponding keys. It involves defining configurations to specify the areas, keys, and filters for mapping.
Inputs & Outputs
- [I] Extracted words (
list<object>): The output extracted from a PDF using the PDFExtract Textaction. - [I] Area configuration (
list<json>): List of JSON objects containing configuration options for a set of areas. - [O] Mapped areas (
list<object>): Key-value list containing value maps for each area.
Configuration Details
The Area configuration JSON structure comprises the following properties:
- MapToKey (mandatory)(
string): Key that will be found in the output data under thekeyfield. - OnPages (optional)(
list<int>): Specify the pages in the document to search. If not specified or <=0, it searches all pages. - BetweenXLeft (
int), BetweenXRight (int), BetweenYTop (int), BetweenYBottom (int), IsBelowWord (string), IsAboveWord (string), IsOnTheRightOfWord (string), IsOnTheLeftOfWord (string), RegExCaseInsensitivePattern (string), RegExCaseSensitivePattern (string) (all optional): These are all optional fields, but at least any 2 fields must be filled to extract text from the pdf. - MaxNoOfRowsPerTarget (mandatory) (
int): Specifies how many rows identified should be considered as a result. Words identified onMaxNoOfRowsPerTargetare concatenated into a single text. E.g. If your data in the pdf is written on 2 rows of text and you want this information from both rows mapped to one key result, then you should set this parameter to 2. - TakeFirstElements (optional) (
int): If null or <=0, it's considered to take all elements. This parameter specifies how many "instances" identified should be put on the output. It does not refer to how many words to consider, but how many "instances" are found.TakeFirstElementsdefines the maximum number of values to output for the MapToKey. Each "instance" can have 1 or more lines of text.
The images below present the configuration parameters visually depicted to express the way they need to be used to extract data from a PDF.
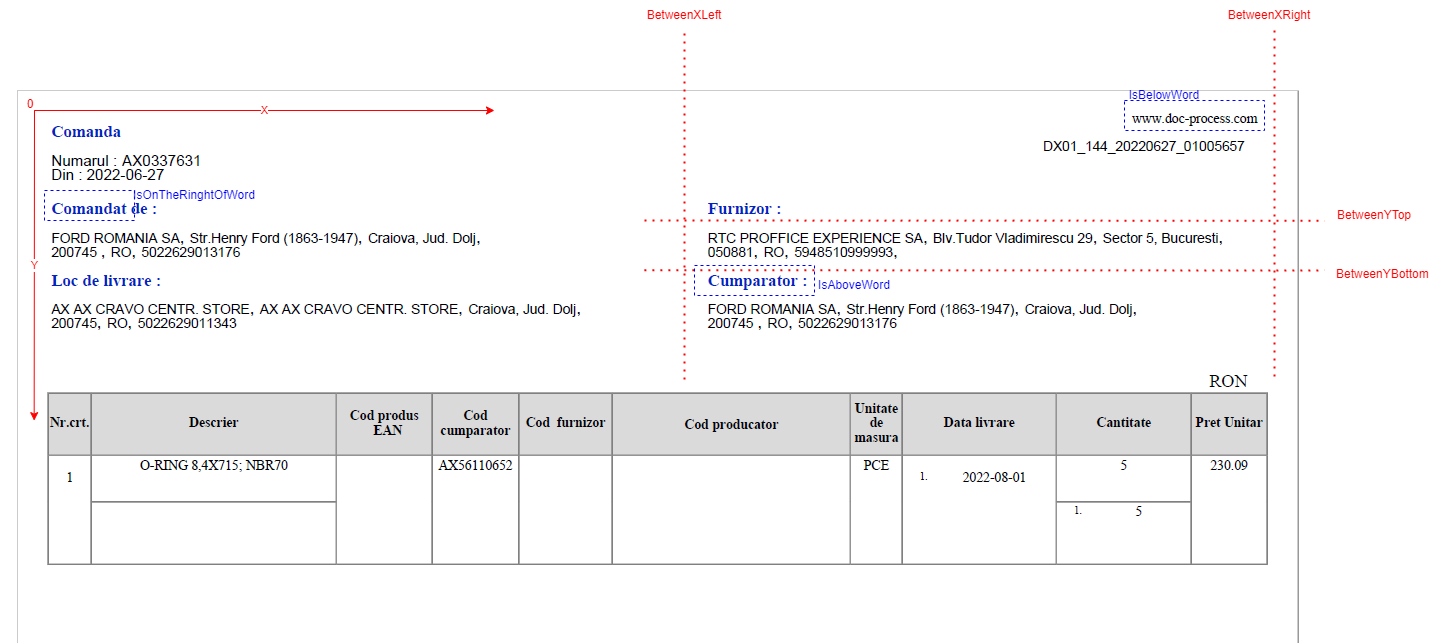
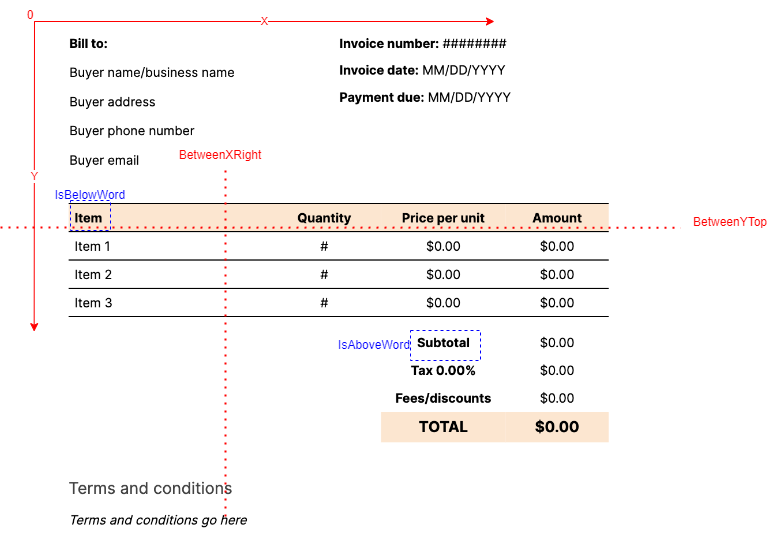
Area Configuration JSON Example 1
[
{
"MapToKey": "VAT number",
"OnPages": [1],
"IsBelowWord": "C.I.F",
"BetweenXLeft": 320,
"BetweenXRight": 448,
"BetweenYTop": 714,
"BetweenYBottom": 696,
"RegExCaseSensitivePattern": "^(RO)?[0-9]+",
"MaxNoOfRowsPerTarget": 1,
"TakeFirstElements": null
},
{
"MapToKey": "IDFactura",
"OnPages": [1],
"IsBelowWord": "Numar",
"BetweenXLeft": 320,
"BetweenXRight": 448,
"BetweenYTop": 755,
"BetweenYBottom": 735,
"IsOnTheLeftOfWord": "Data:",
"MaxNoOfRowsPerTarget": 1
},
{
"MapToKey": "IssueDate",
"OnPages": [1],
"BetweenXLeft": 417,
"BetweenXRight": 505,
"BetweenYTop": 755,
"BetweenYBottom": 740,
"MaxNoOfRowsPerTarget": 1,
"RegExCaseSensitivePattern": "\\b\\d{2}\\.\\d{2}\\.\\d{4}\\b"
},
{
"MapToKey": "Bank",
"OnPages": [1],
"IsBelowWord": "Bank:",
"BetweenYTop": 43,
"BetweenXLeft": 283,
"BetweenXRight": 360,
"BetweenYBottom": 37,
"MaxNoOfRowsPerTarget": 1
},
{
"MapToKey": "BankAccount",
"OnPages": [1],
"IsBelowWord": "Konto:",
"BetweenYTop": 43,
"BetweenXLeft": 433,
"BetweenXRight": 529,
"BetweenYBottom": 37,
"MaxNoOfRowsPerTarget": 1
}
]Mapped area output JSON Example 2
The JSON below is an output example for the above Area Configuration JSON Example.
[
{
"page": 1,
"key": "VAT number",
"values": [
"12345"
]
},
{
"page": 1,
"key": "IDFactura",
"values": [
"4444444444"
]
},
{
"page": 1,
"key": "IssueDate",
"values": [
"14.09.2022"
]
},
{
"page": 1,
"key": "Bank",
"values": [
"Bank Name FAKE"
]
},
{
"page": 1,
"key": "BankAccount",
"values": [
"RO99 FAKE 0000 000X XX00 00000"
]
}
]Important Notes
- Ensure that the necessary configurations accurately map the desired areas to keys.
- Verify the output to ensure the expected values are correctly mapped.